tl;dr — Yes. We’re messing with Search Console data when we scrape SERPs with hourly tracking.
A month or so back, I launched a new site for a local small business and set up all the usual tracking; Analytics, Search Console etc.
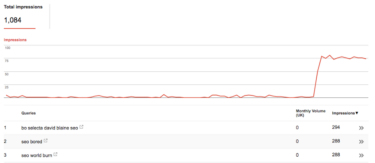
When checking in on Search Console a week or so later, I was surprised to see the following for the main brand term;

365 impressions over a week with similar volumes each day, for what shouldin theory be a very low volume search term? Either something was wrong, or people were searching for their business way more than I’d expected which, sadly to say, is unlikely.
Out of curiosity, I’d set up our hourly rank tracking service prior to submitting the site to GSC, in an attempt to see how quickly pages were indexed and how long they took to rank. This got me thinking — could this be the source of the heightened impressions?
What’s an impression anyway?
According to the definition of an impression from Google…
“A link URL records an impression when it appears in a search result for a user”
Essentially, every time a URL from your site appears in a SERP, that’s one extra impression. If you’re lucky enough to have two URLs appear in the same SERP you’ll get two impressions, and so on.
Google seemingly doesn’t require that a result be scrolled into view or anything fancy, so it’s feasible that our (JavaScript-enabled) scraper could be causing this.
Testing the theory
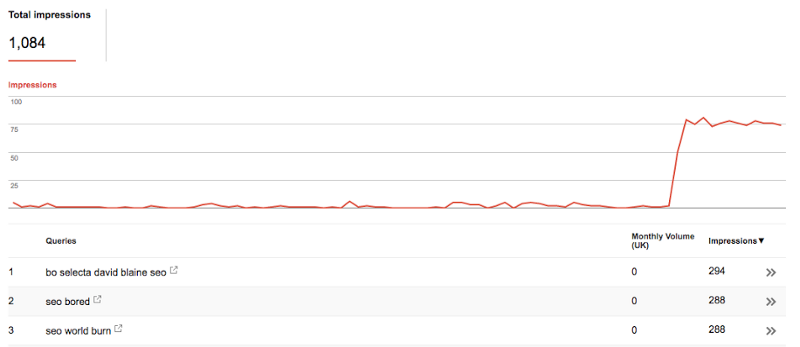
The test for this was pretty simple; just turn off the tracking. I did that, and this was the result…

On top of this, we’d also been running another experiment for our colleague Dan, who was noticing the same thing with his site across the terms which we were running the test on…
Conclusion
I should probably preface this by saying that this was a small-scale and not very scientific test, so take this with a pinch of salt.
However, yes — it seems that rank tracking is inflating the reported impressions.
We can see that Google doesn’t differentiate between a real user and our scraper — at least not for the purposes of Search Console data. This is probably because, given the restrictions in place to prevent scraping, the bot needs to look as much like a person as possible to avoid detection — making Google’s job harder.
Our hourly tracking isn’t normal, so let’s talk in real terms. Say we’ve got a campaign tracking 300 keywords daily on both desktop and mobile. Even if our site only ranks for half of those terms, that’s at least 9,000 false impressions each month reported through GSC. You likely won’t be the only person interested in tracking this too, so that number can multiply for each site owner / ranking data provider.
So what’s the impact of this for you?
Search Console data has long been seen as unreliable, but this makes the situation even worse.
If you’re looking at high-volume keywords, the impact is probably more limited. For lower volume terms like those we looked at though, it complicates things somewhat if you’re hoping to make any kind of educated decision from the data, or if you report on it to clients at all.
It’s worth keeping in mind that, whilst we haven’t verified this, the impact may spread to more Google products than just Search Console. If there’s crossover with Google My Business or Keyword Planner, we could be making ill-informed decisions on our marketing efforts.
Whilst there’s not much you can do to stop this happening, it’s another friendly reminder to not take all data at face value!
As a closing note; I’d be curious to see as to whether this manipulation of Google’s data could be used for gain. Knowing that Google are quite likely using click data to influence rankings (even as far back as 2014), could a machine-learning backed model learn how to game the system via fake clicks / UX metrics like time on page?
If you’re interested in trying out hourly rank tracking for free and running these kind of experiments with us, let us know!
















