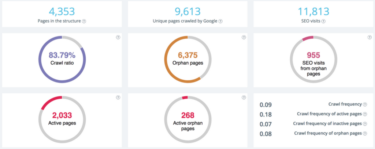
Logfile analysis is quickly becoming the new standard in technical SEO. This doesn’t mean it’s a “new thing” (before some of you start berating me), as long as SEO has been a recognised practice people have been diving into server logs to see how Google is crawling their site.
However, for those of you who don’t have a development background, or who aren’t familiar with the process, this can be riddled with problems and roadblocks.
But based on the power of log file analysis and what this can mean for your SEO strategy, I think we’d all be agreement this needs further time to focus on. Francois from OnCrawl gave a really good run through the process at BrightonSEO in September in case you missed it.
Does This Sound Familiar?
You email your developer and let them know you’re completing an SEO analysis. Assuming you’ve got a working relationship with them, they’ll want a bit of clarity on “which logs?”. In fairness there’s a lot of logging going on, you’re going to have to be more specific.
You go back to them asking for server logs, wait X days or weeks and they send you:
“2017_06_01_security_log”
Nope, not quite! Maybe you should have been more specific. You clarify and request “access logs”, wait a bit longer and you get something you can work with. This process can be as little as a few minutes, to a few weeks (depending how long the development queue is).
If this is familiar to you, I feel your pain — stick with me though, it’s worth it.
Knowing What You’re Asking For
Step one of getting your log files; you’re looking for server access logs, not error or security logs. In some scenarios these logs could all be combined, or they may be named/labeled differently, but it’s the resources accessed from the server you’re interested in.
Typically, they look like:
access_log
access_ssl_log
access_log.processed
*access_log.processed.2.gz
These are all examples of access log filenames, whether they’re for SSL or non-SSL requests (sometimes combined) processed or gzipped (.gz).
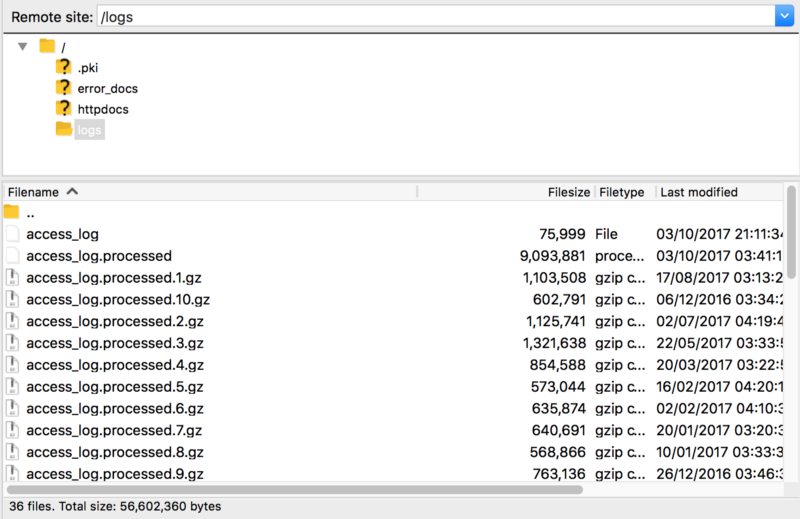
When you receive them you should be able to extract and then open with a text editor or IDE. They’re not all that useful in this format, but in case you’re wondering they usually look like this:

I’m not going to go into how to use logs for your SEO analysis here, but traditionally excel or grep skills are favoured. Many tools have entered the ring over the last few years, here are a few to consider depending on budget:
I’ve met strong advocates for all the above, and certainly they’ll all give you what you need to undertake a strong SEO audit. BuiltVisible have also produced a pretty epic guide on log file analysis which you can find here.
Can You Find Them?
Locating log files can be tricky to the uninitiated. I have seen/heard developers ask where they’re found, so if you know where to start looking, this can help. Again, coming from a total non-dev here, my understanding is that logs (on Apache servers) are typically located in the /var/log/apache2 or /var/log/httpd directories. On Nginx is /var/log/nginx or logs/, again by default and for IIS %SystemDrive%inetpublogsLogFiles.
If you’re running Cpanel or Plesk you can locate the logs without FTP — In Cpanel click “Raw Access Logs” or “Logs”, for Plesk, here is good guide to locating it.
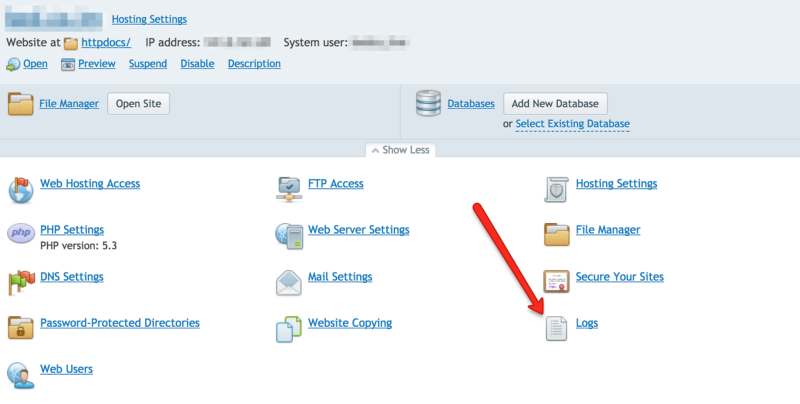
This is rendered useless if someone has changed the location where the logs are stored (very possible/likely), but assuming that if they’ve been changed someone will know where they are.
If Access Logging Isn’t Enabled
This is something you don’t want to hear if you’re ramping up for a new audit — primarily because it means you won’t have any data to work with. Enabling logging is relatively simple to do, however, what you need to get to the bottom of here is why it has been disabled in the first place.
In the vast majority of cases this is because logs files are huge and if left unchecked could eventually stop a server in its tracks. There are different ways around overcoming this, and these’ll depend on how much time/resource you have at your disposal.
At minimum, if you can store only 30 days worth of logs this is a good start. Failing that, you can request the logs are dumped elsewhere on the server (or another server) for storage, for one-offs or regular monitoring.
“We Can’t Give you Access to the Logs”
You’ll hear this a lot, here are some of the possible translations:
- I don’t want to give you access
- I don’t know how to give you access
- I really can’t give you access
#1 is a tricky situation, very rarely will someone flat out say they don’t want to give you what you’re looking for, but there’s very likely a timing/prioritisation clash you’ll need to get around. This will take your powers of persuasion to sell the virtues of why you’re doing what you’re doing.

If, after some discussion, it transpires that whoever is responsible from the website doesn’t know how to give you log access (not as rare as it sounds!) then the above may help.
The real tricky part comes when they cannot give access, whether it’s security policies or data protection stopping you. Do take some time to find out what exactly is the issue — and push the point if it’s really important to your campaign (it is!).
Believe it or not, it isn’t a big ask to ensure that only logs of Googlebot requests are exported for you — this could be a workaround in some cases.
Remember, be tenacious, learn about the issue and find you way around it.
Go on — get those logs!
Logfile analysis is a new rite of passage within SEO, you can separate tech SEOs between those who have and those who haven’t. I firmly believe you can be an effective tech SEO without logs, but with some sites it can be very much like fighting with one arm tied behind your back.
You won’t necessarily have all the answers with this blog, but it should arm you with the knowledge to go forth and start your access log journey with SEO.
Get going!

















